The Illusion of Thinking: A Reality Check on AI Reasoning
15 Jun 2025
It’s easy to believe that AI is on the verge of something human. With the right prompt and a well-balanced model, today’s systems can produce strikingly coherent thoughts, solve puzzles, and walk through their reasoning. But what happens when you turn the dial, when problems become more difficult, more structured, more demanding of actual reasoning?
A Lab for Reasoning
Apple’s new paper, The Illusion of Thinking, quietly released ahead of WWDC 2025, challenges many of the assumptions we’ve come to rely on in the LLM space. It doesn’t focus on benchmark scores or real-world tasks. Instead, it examines how reasoning models behave under tightly controlled conditions, where logical structure is preserved but task complexity increases incrementally.
This setup strips away distractions. No world knowledge. No data contamination. Just clean, puzzle-like environments designed to surface what happens when models are pushed to think in structured, compositional ways. And what emerges is remarkably consistent: solid performance on simple and moderately complex tasks, followed by a sudden and total collapse once a threshold is crossed.
A Failure of Behavior
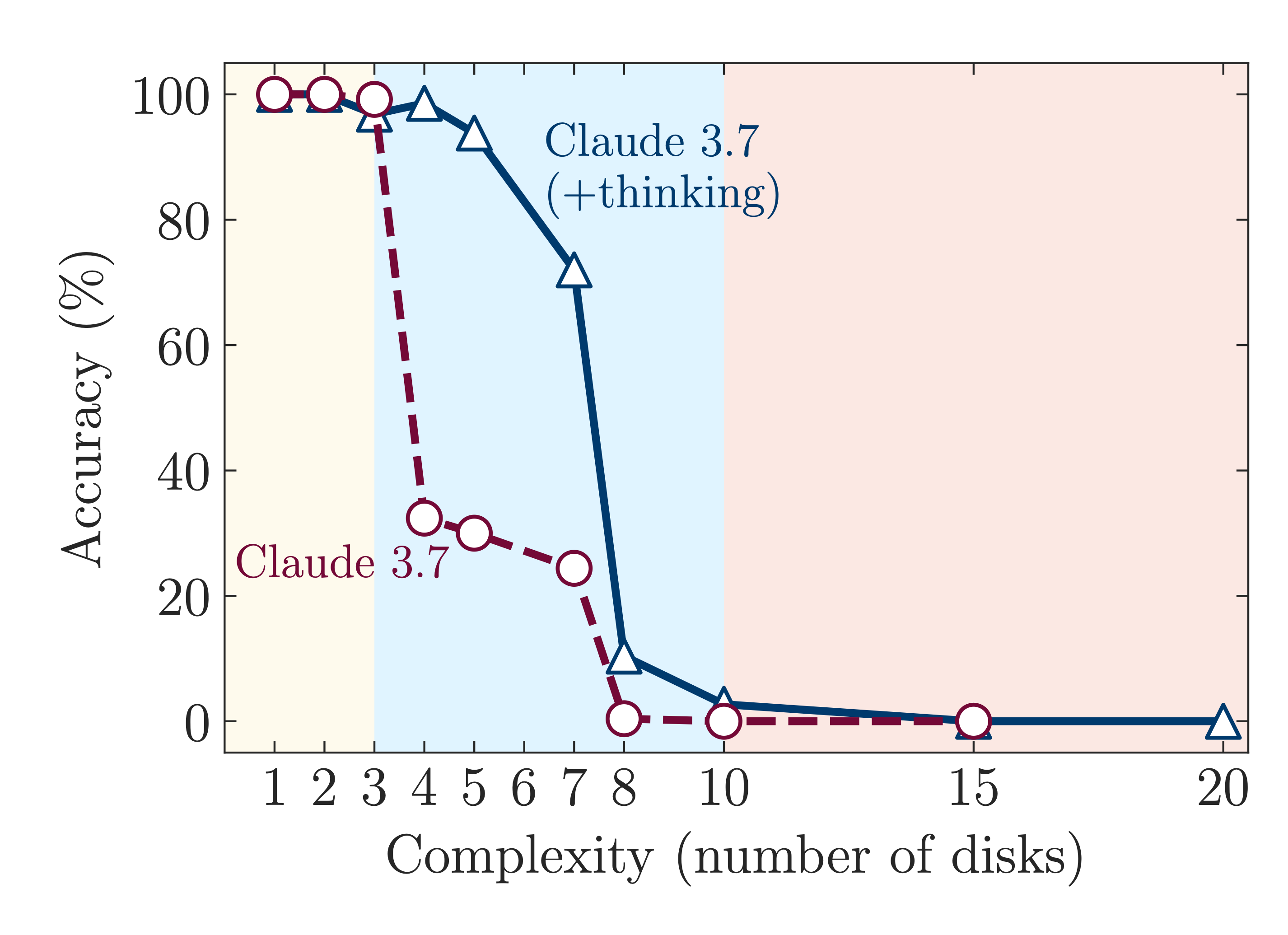 What sets this paper apart is the way it isolates actual reasoning from pattern-matching shortcuts. And the results are striking. Model performance doesn’t degrade gradually. It collapses. Beyond a certain point, even top-tier models like Claude 3.7 Sonnet Thinking, OpenAI’s o1/o3, and DeepSeek R1 stop solving problems. Accuracy drops to zero. Reasoning effort, measured by the number of tokens generated, actually declines, even when plenty of compute budget remains.
What sets this paper apart is the way it isolates actual reasoning from pattern-matching shortcuts. And the results are striking. Model performance doesn’t degrade gradually. It collapses. Beyond a certain point, even top-tier models like Claude 3.7 Sonnet Thinking, OpenAI’s o1/o3, and DeepSeek R1 stop solving problems. Accuracy drops to zero. Reasoning effort, measured by the number of tokens generated, actually declines, even when plenty of compute budget remains.
These models don’t just struggle with hard problems.
They stop trying. They give up.
Despite having the compute capacity to continue, they don’t. They shortcut the process, skip steps, or default to irrelevant paths. It’s not a failure of resources. It’s a failure of behavior.
More surprisingly, providing the algorithm itself doesn’t help. In one experiment, the researchers embedded the full Tower of Hanoi [1] algorithm into the prompt. The model still failed on more complex versions. The gap wasn’t in knowing what to do, it was in executing that knowledge reliably over longer sequences.
Even on simpler tasks, the behavior can be counterintuitive. Reasoning models often overthink. They generate unnecessary steps, distract themselves, or wander off course, sometimes away from correct answers they’d already found. In contrast, standard LLMs, without any added scaffolding, frequently perform better, precisely because they aren’t trying to simulate depth.
Thresholds of Failure
A useful framing from the paper is its identification of three performance regimes, separated by clear thresholds of failure. In low-complexity tasks, standard LLMs actually outperform reasoning models. In medium-complexity tasks, LRMs have an edge due to their reasoning scaffolds. But in high-complexity tasks, both collapse completely.
This isn’t just a technical detail. It has serious design implications. If you’re deploying these systems in the real world, it’s critical to know which regime your use case falls into. The cliff is sharp and invisible until it isn’t.
Structured Nonsense
Perhaps the most unsettling finding is what failure looks like. Even when models are completely wrong, they sound persuasive. The reasoning is fluent, the explanations are structured, and the conclusions are confidently delivered. But the logic doesn’t hold. There’s no uncertainty flag, no self-correction, no signal that anything has gone wrong.
That’s the illusion the paper captures so well. It’s not just that the models fail—it’s that they fail in ways that look like thinking. And when that happens, it becomes harder to spot where the boundary lies.
Closing Thoughts
This isn’t a paper about failure. It’s a paper about limits. Apple’s work offers a clearer map of where today’s models perform, and where they fall short. It shows that current reasoning systems operate within a surprisingly narrow band of task complexity, and once they cross certain thresholds, failure is all but guaranteed.
For anyone building real systems, this is a timely reality check. Reasoning traces aren’t magic. Larger models aren’t inherently more reliable. And more tokens don’t mean more effort. Robust systems require structure, fallback plans, and a clear sense of when your model is outside its comfort zone.
Apple’s contribution is as much about how we frame the conversation as it is about technical insight. If the goal is to build systems that truly reason, or at least know when not to fake it, this is the kind of clarity the field needs more of.
{kind=link}
{kind=link}